

The ‘artists’ node in our Firebase database
In Firebase, Google’s ‘NoSQL’ database, you can declare indexing by any of a node’s children in order to optimize retrieval by that field.
For instance, under a node called ‘artists’ where the keys are the artist’s ‘uid’ and the values are artist objects, the default indexing is by uid.
While you could retrieve the artists, specifying in the query that they be ordered by display name, it’s not efficient. If you expect to retrieve artists by display name often, then you should declare an index, like so:
"artists": {
".indexOn": ["user/name/display"],
...
}
But let’s say you want to support a predictive search function where the user chooses a genre and begins typing an artist’s name.
As they type, users should see a dropdown list containing the first five artists in the chosen genre whose name matches the input so far. You can specify a limit to the number of items returned in the query, so as long as they’re in the desired order, populating the predictions list should be simple and quick.
Firebase Supports Simple Key Indexing
You’ll notice in the example above that the .indexOn field takes an array — you can index on more than one field, like genre name. However, the results wouldn’t ALSO be in order by artist display name. It would be optimized for retrieval by artist display name OR by genre, but not by both. For that, you need compound keys, which aren’t (currently) supported in Firebase’s rule language. That is, in the .indexOn field, we cannot specify multiple fields to make up a single compound key. I suspect that will happen at some point, but for now, we have to tackle the problem ourselves.
We could create an ‘artist_by_genre’ field on the artist object and tell Firebase to index on that field. We’d need to concatenate the genre and artist display name together on the client and store it in that property before saving the artist object.
If the fields making up the compound key aren’t on objects inside collections, then this approach is fine. For instance, postal code and artist name would work and we could retrieve artists alphabetically within a given postal code as easily as by any other simple field.
In our case however, we need to support multiple index entries for each artist, since an artist (as in the one shown above), can work in multiple genres.
Implementing a Compound Key Index

The ‘artist by genre’ index
First we need to create another node to hold the key/value pairs that will make up our index. The keys will be genre name and artist display name concatenated.
As you can see, we are easily able to accommodate multiple index entries for the same artist using this key scheme.
And since the index is naturally ordered by the key, the data will be alpha by genre, and within that, alpha by artist display name.
From the data structure alone, you can see that using a compound key strategy is not that hard to implement. The only question is what should the key’s value be?
We could just make it be the uid of the artist, and then make a separate call for the artist node, but that’d be chattier than is desirable in a predictive search query, where we’re already making queries to get the first five artists in the genre whose display names match the user’s input as they type. Making another five calls when each of those queries return be way too much.
You shouldn’t fear duplicating data — disk is cheap and speed is dear. The important thing is to store all the data you need to fulfill every use case that reads this index.
So we could just write the entire artist object here at this node. But it might be a big object, and contain much that is extraneous for our purposes. In our case, we just want to have the dropdown list contain the name of the artist, and possibly a thumbnail profile image. When the user actually selects an artist from the list, then we can make a single call to grab the full artist profile object from the /artists node.
Maintaining the Index
When an artist writes a profile object to the /artists node, the artists_by_genre index also needs to be updated. The first time the profile is written, it is sufficient to just write a key/value pair for each genre in the artist’s profile. But when they update their profile, changing their name or perhaps modifying the genre list, it gets more involved. You need to remove the old entries and add the new ones. That could mean four or five writes for each artist when updating their profiles.
Now, in this particular scenario, doing five writes to update an artist by genre index might not be that much chattiness even at scale. You could optimize that by comparing the old genre list and the new one and determining if the name had changed, of course.
But you might have a scenario where you are writing and deleting entries in a compound key index more frequently and with higher volume. Not only is it cumbersome to include the client code to manage this index, it’s also much chattier than one might like.
Using Firebase Cloud Functions as Stored Procedures
An exciting new feature of Firebase is Cloud Functions. A Firebase Cloud Function is just that: a function, written in JavaScript, deployed in Node.js, which can be triggered by a variety of inputs:
- Realtime Database Triggers
- Firebase Authentication Triggers
- Firebase Analytics Triggers
- Cloud Storage Triggers
- Cloud Pub/Sub Triggers
- HTTP Triggers
It’s the ultimate in micro-services. Inside your Cloud Function, you can do pretty much anything your heart desires. In our case, we’re going to use it like a traditional SQL Stored Procedure.
When a child of /artists is written, we want to have our Cloud Function fire and update our artist_by_genre index for us.
Having a database up and running already, we’ve initialized our project for Firebase and are logged in through the Firebase CLI. In order to add a Cloud Function, we just need to enable that feature. In our project’s folder, we’ll initialize Firebase Cloud Functions:
firebase init functions
Now the project has the following Firebase-related configurations (the functions folder was just added):
project +- .firebaserc # EXISTING - Hidden file that helps you quickly switch between | # projects with `firebase use` | +- firebase.json # EXISTING - Describes properties for your project | +- functions/ # NEW - Folder containing all your functions code | +- package.json # NEW - The npm package file describing your Cloud Functions | +- index.js # NEW - Main source file for your Cloud Functions code | +- node_modules/ # NEW - Folder for Cloud Functions dependencies
The functions/index.js file is where we will add our Cloud Function(s).
exports.indexArtist = functions.database.ref('/artists/{uid}')
.onWrite(event => {
// All the write promises this function will create
let writes = [];
let artistByGenreIndex = admin.database().ref('/indexes/artist_by_genre');
console.log('Triggered by artist', event.params.uid, event.data.val().user.name.display);
// Remove any previous entries since genre or display name may have changed
var previous = event.data.previous.exists() ? event.data.previous.val() : null;
let deletes = [], key, val;
if (previous && previous.genres){
console.log('Removing old index entries...');
previous.genres.forEach( genre => {
key = genre.name + previous.user.name.display;
deletes.push( artistByGenreIndex.child(key).set(null) );
});
console.log(deletes.length+' entries removed.');
}
// If any previous entries were deleted, wait until they finish
Promise.all(deletes).then(addKeys).catch(addKeys);
// You must return a Promise when performing async tasks in a Firebase Cloud Function
return Promise.all(writes);
// Add the keys for all Genres this Artist has chosen
function addKeys() {
const current = event.data.exists() ? event.data.val() : null;
if (current && current.genres) {
console.log('Indexing artist: ', event.params.uid, current.user.name.display);
current.genres.forEach( genre => {
key = genre.name + current.user.name.display;
val = {key: key, artist: {user: current.user}, genre:genre};
writes.push( artistByGenreIndex.child(key).set(val) );
});
}
}
});
Notice in the above code, we did not have to specify any credentials. That’s because it’s deployed to the server where the database lives, and is part of our project. Also, we are using the Firebase Admin SDK to write the index, which means we can deny write privileges to everyone in the database ruleset for the artist_by_genre node. Here’s a GitHub Gist of that code.

Artist by genre index rules
Now, with our function written and rules applied, all we need to do is deploy the function and then write to the database to see if it worked.
firebase deploy --only functions
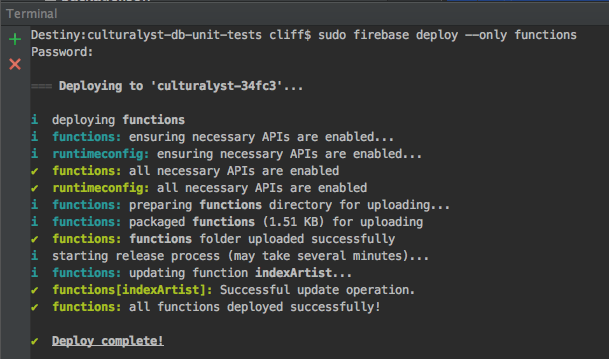
Deploy Firebase Cloud Functions
At any time, on the Firebase Console for our project, we can see what functions are deployed, and some info about their executions. And after writing an artist to the database, we can immediately see the Cloud Function’s output by choosing that function and selecting ‘View logs’.

Deployed Cloud Functions
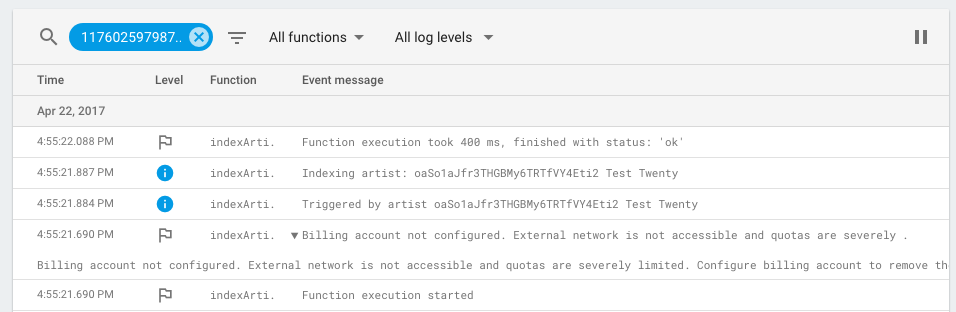
Firebase Cloud Function Log
All of our console output is available in addition to timing and system messages, such as the warning that we need to upgrade to a paid plan if we want to access external APIs or raise our usage quotas.
And the proof is in the pudding, so to speak. The artist_by_genre index contains the proper data (the above index entries were written by this Cloud Function).
Conclusion
Composite key indexes with multiple keys per source node are often needed but currently unsupported by Firebase. While we can create a special node to hold the key/value pairs that represent such an index, it could be cumbersome and chatty to include in a client application. And if multiple client applications with different codebases are accessing the same database, then duplicating the logic to maintain the composite key indexes could be even more onerous.
Firebase Cloud Functions are a powerful solution to the problem, and can be used in the same way that you would a stored procedure in a traditional RDBMS. They are easy to build, deploy, and maintain. This centralizes the mundate indexing logic and reduces network chatter.
I hope this helps you out in your next big Firebase project.