
OR
How I Learned to Stop Worrying and Love the Black Box
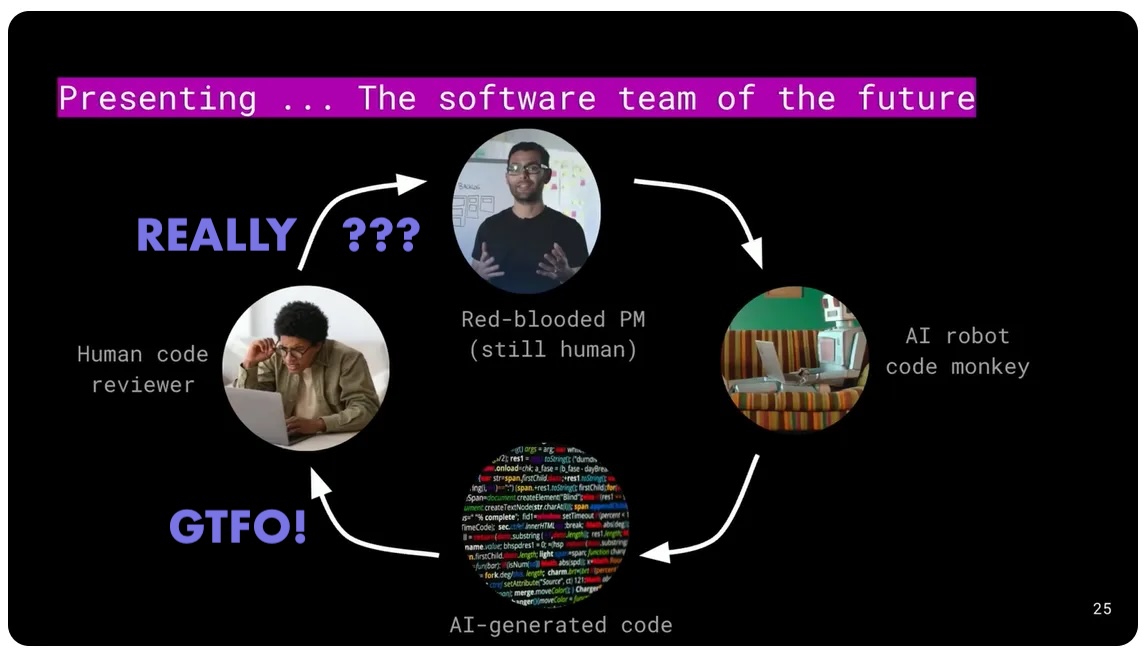
Is this what we’re headed for? [Original Image Credit: The New Stack]
The above diagram comes from an article called “If Computer Science Is Doomed, What Comes Next?” which concludes that we will let the AI do the work and relegate humans essentially to responding to pull requests with code review. This may represent the software team of the near future, but beyond that, it doesn’t make much sense to me.
For a while, we’ll be ok with this arrangement, but the AI will get better, until no one really reviews the AI’s work, they just rubber stamp the PRs because it’s never wrong.
At that point, we’re only there because we think we have to be, and our presence is only slowing the AI’s performance.
Inside the Black Box
So, what happens if we take the human out of the loop entirely?
Humans use high-level languages that compile down to machine code because writing machine code is tedious.
If machines are writing and running the code and we trust that they get it right and we can verify it, then it makes no sense for them to write that code in a high level language that must then be compiled down to machine code, and modified along the way by the compilers — optimized with human algorithms. We’re still in the loop!
Machines can probably write better compilers when they outstrip the 10x dev at her game. But again, why use them at all? If a program is compiled inside an AI and no human reads it, was the source code elegant?
Measuring the Performance of Black Boxes
We will give AI requirements for new systems, and we will measure the output of those systems and judge if they meet specifications, like measuring fuel pressure in a rocket. If it doesn’t meet spec, you shut it down.
If you have clear requirements and can measure output against expectations, why do you care how a program works inside?
Then the focus shifts from verifying “did the code that was generated look good to a human developer” to “does the output of this code when running (e.g., user interfaces, input recognition, data processed, stored, or otherwise transmitted) meet exacting specifications for the software’s function?”
I heard an anecdote some time ago about a new RISC processor and the community of devs trying to build the first tools for it. One of the things folks were working on was sorting algorithms. Everyone was trying to sort the same randomized dataset and get the best speed with the least amount of code. Having the most clever sort routine was quite the flex in certain circles.
One developer applied a genetic algorithm. It basically queued up a bunch of random instructions into the processor, let it run and then evaluated the state of the data. Was it objectively closer to being sorted? If so, he kept half the instructions and added more random ones for the next run. If that did better, he continued, otherwise he used the other half with random filler. Again and again.
Eventually, after many iterations, he had a sort routine that crushed the best human efforts by a long shot.
But when they inspected the code, no one could understand it. It did not seem to make any sense. Yet that tiny packet of code operated better than any human at the same task.
This was a genetic algo, not an AI, but same difference. In the end, if you wanted to employ the fastest sort on that CPU, you had to accept the fact that you could not understand how it worked. The proof was in the pudding.
The hard and crucial part, of course, was analysing the sortedness of the output. Verification of function.
But sort routines are not as complex as, say a CRM system or the code to control an autonomous vehicle.
As the size and impact of a black box’s operation increases, what our QA departments do suddenly becomes incredibly important and mission critical. On the heels of the developer cutbacks, companies that previously thought they couldn’t afford QA staff will now be laser focused on acquiring the best talent in that field.
They are the ones who are testing how the system works, not how it was written.
Developers know how a system should work and build it mostly with the expectation that interactions will generally follow the happy path. Unit tests of their code convince them that all the bits and bobs they’re stringing together work as expected.
QA engineers think of a million ways to break it. Ways you never thought of in your ones-and-zeros devbrain. That is why they’re indispensable now, and will be even more so as we devs turn off the lights on our way out.
Surrendering To the Black Box
Think about how many companies lacking development as a core competency outsource software projects to agencies, trusting that the code will just do the right thing. This observation is not about whether it’s wise to trust agencies and consultancies with your projects if you don’t want to run a dev operation in-house. Usually it works out just fine.
It’s about the fact that very often, the owners of software are not really aware of how it works, only that it does what they want it to do. It’s ok for it to be a black box if you are happy with what it does.
A lot of software we interact with every day falls into this category already. I don’t know how Wordfence works, I just know that if I want my WordPress site not to go down every 5 minutes from hacks, I need it. It’s a black box to me, and that’s ok. If it verifiably did the same job but was created entirely by unsupervised AI, I’d still be a subscriber.
Those will be the low hanging fruit.
More complex systems like self-driving will be interesting. Imagine focusing all human effort on testing and verification rather than trying to figure out the best algos for a processing a million little sensors into a worldview of high enough resolution to make life and death decisions on the way to the bakery while also reconciling any particular implementation with that old philosophical chestnut, the trolly problem and the legal department.
If a system could pass all human best efforts at verification of function in real world scenarios for billions of hours, would it matter if we couldn’t understand how it works? And in fact, the lawyers could breathe a sigh of relief, since no one had to commit a trolly-problem decision to code and put it in a car. Protect the driver or protect the pedestrian? It was never decided. It’s like Schrodinger’s Cat; we don’t know until we observe the actual event, what seems to have happened. If traffic fatalities go down as a function of autonomous, AI-controlled vehicle adoption, we’ll know we got it right. Not because autopilot code passed a suite of unit tests.
We will learn to trust the behavior of the car while accepting that the real world will always produce situations that are suboptimal. We will stop worrying and learn to love the black box.
Conclusion
AI is coming up behind us, certainly. But most of the coders I’ve talked to aren’t worried that our whole profession is doomed. The general vibe is more “Your dev job won’t be taken by AI, it’ll be taken another dev with AI.”
I personally don’t expect to be put out of work by AI anytime soon, but one day, I accept that it will come to pass. And I will not be happy with becoming a bureaucrat who approves PRs for a living.
Learning to collaborate with the AIs and how to verify what they create formally seems like the obvious next step for developers. We understand complex systems well enough to architect and build them, we can certainly specify and verify them.