

I was recently doing a JavaScript code review and came across a chunk of classic imperative code (a big ol’ for loop) and thought, here’s an opportunity to improve the code by making it more declarative. While I was pleased with the result, I wasn’t 100% certain how much (or even if) the code was actually improved. So, I thought I’d take a moment and think through it here.
Imperative and Declarative Styles
To frame the discussion, imperative code is where you explicitly spell out each step of how you want something done, whereas with declarative code you merely say what it is that you want done. In modern JavaScript, that most often boils down to preferring some of the late-model methods of Array and Object over loops with bodies that do a lot of comparison and state-keeping. Even though those newfangled methods may be doing the comparison and state-keeping themselves, it is hidden from view and you are left, generally speaking, with code that declares what it wants rather being imperative about just how to achieve it.
The Imperative Code

Let’s break down the thought process required to figure out what’s going on here.
- JavaScript isn’t typed, so figuring out the return and argument types is the first challenge.
- We can surmise from the name of the function and the two return statements that return literal boolean values that the return type is boolean.
- The function name suggests that the two arguments may be arrays, and the use of needle.length and haystack.indexOf confirms that.
- The loop iterates the needle array and exits the function returning false whenever the currently indexed value of the needle array is not found in the haystack array.
- If the loop completes without exiting the function, then we found no mismatches and true is returned.
- Thus, if all the values of the needle array (in any order) are found in the haystack array, we get a true return, otherwise false.
The Declarative Code
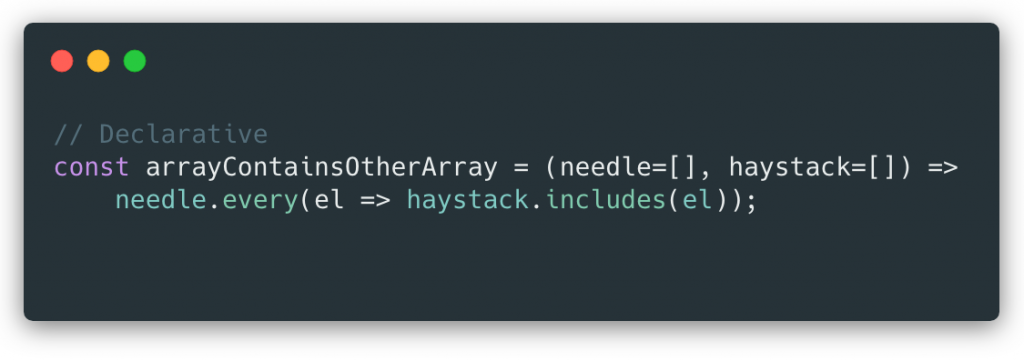
Note: Tip o’ the propeller beanie to Michael Luder-Rosefield who offered this solution which is much simpler than the previous version which used reduce.
That took fewer lines, but you still have to break it down to understand what it’s doing. Let’s see how that process differs.
- JavaScript isn’t typed, so figuring out the return and argument types is the first challenge.
- We can surmise from the name of the function and the returned result of an array’s every method that the return type is boolean.
- The function name suggests that the two arguments may be arrays, as do the default values now added to the arguments for safety.
- The needle.every call names its current value ‘el‘, and checks if it is present in the haystack array with haystack.includes.
- The needle.every call returns true or false, telling us, quite literally, whether every element in the needle array is included in the haystack array.
Comparisons
Now, let’s weigh the relative merits of each implementation.
Imperative
Pros
- The syntax of the venerable for loop is known by all.
- The function will return immediately if a mismatch is found.
- The for loop is probably faster (although it doesn’t matter much at the small array size we’re dealing with).
Cons
- The code is longer: 7 lines, 173 characters.
- Having two exits from a function is generally not great, but to achieve a single exit, it would need to be slightly longer still.
- While the loop does iterate the entire length of the needle array, it has to be explicit about it, and we need to visually verify the initializer, condition, and increment inspection. Bugs can creep in there.
- Comparing the result of the haystack.indexOf call to -1 feels clunky because the method name gives you no hint about what it will return if the item isn’t found (-1 as opposed to null or undefined).
Declarative
Pros
- The code is shorter: 2 lines, 102 characters.
- The function will return immediately if a mismatch is found.
- The result of a single expression is returned, so right away it’s obvious what the function is attempting to do.
- The use of needle.every feels satisfying, because the method name implies that we’ll get a true or false result, AND we don’t have to explicitly manage an iteration mechanism.
- The use of haystack.includes feels satisfying, because the method name implies that we’ll get a true or false result, AND we don’t have to compare it to anything.
Cons
- The every call is probably slower (although it doesn’t matter much at the small array size we’re dealing with).
Conclusion
Both of these implementations could probably be improved upon. For one thing, and this has nothing to do with imperative vs declarative, the function name and arguments could be given clearer names. The function name seems to indicate that we want to know if one of the arrays is an element of the other. The argument names actually seem to reinforce that. In fact, we just want to know if the contents of the two arrays match, disregarding order. This unintended misdirection creates mental friction that keeps us from readily understanding either implementation upon first sight.
Aside from naming issues, it looks like the declarative approach has more pros than cons, so on a purely numerical basis, I’m going to declare it the winner.
Implementing declarative code is widely expected to enhance readability. How it affects performance is another question, and one that should certainly be considered, particularly if a lot of data is being processed. If there isn’t much performance impact, then a more readable codebase is a more manageable codebase.
If you see other pros or cons I missed for either of these contenders, or take issue with my approximation of their merits, please feel free to leave your comments. And again, thanks to Michael Luder-Rosefield for doing just that on the Medium version of this post.
Excellent, simply excellent.
You literally explained it to a 5th grader and that’s where I was stuck; “no abstractions”, yea, right; how about unit testing, lol. Thanks for writing this.